
Industry roundup #10
Reviewing the 2025 MAD (Machine Learning, AI & Data) landscape

Every year Matt Turck publishes a market map and state of the union about ML, Data and AI. This year’s edition (the eleventh) came out in October and I took some time to go through it. The map is usually huge, with more than 2,000 logos in there, but this year they substantially cut the logo count, which went down to ~1,000. The high res map is available here.
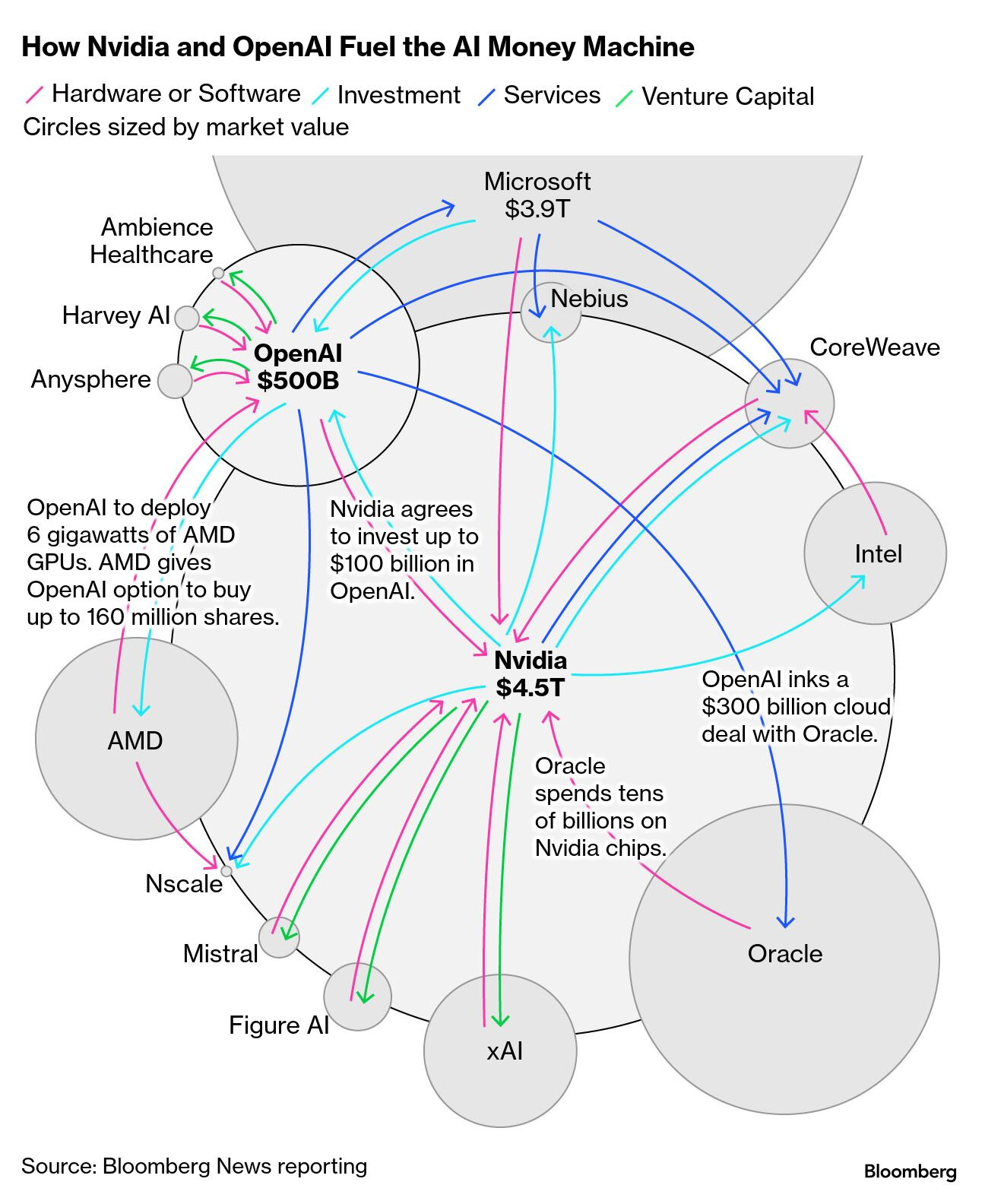
One of the themes is the concern that an AI bubble is in the making:
As tends to be the case in paradigm shifts, capex/opex are front-loaded. Demand will need to materialize in a big way if the space is to stick the landing, but habits often take time to change and adoption is uneven. […] The paradox of 2025 is that hype and fundamentals are both up; history suggests fallout can arrive before the payoffs. […] Under the big growth numbers, a lot of money is looping around a small set of players.
I agree with this take. In my opinion, AI is here to stay and it will be impactful and valuable, but an AI bubble is not a question of “if” but rather “when” and “what type”. This chart does not look good and it does not help reduce the concerns.
Matt also highlights the fight between Big Tech incumbents and challengers (new and established ones):
Big Tech has massive distribution, huge product suites, and budgets to bundle, wait out cycles, and grind. […] Independent frontier labs, by contrast, need step-change breakthroughs to justify valuations. New names (SSI, Thinking Machines, Reflection) joined the top tier, right as agent/reasoning heat rose (and distribution hurdles remained). OpenAI remains the clear leader and keeps raising war chests; Anthropic isn’t far behind, but how long can capital run at those levels? […]
Distribution beats invention (again). A whole generation of AI-native startups is growing faster than we’ve ever seen. Products go viral on social, boards continue to fret about AI and curiosity fuels a wave of trials and tinkering. The open question is durability: true ARR or experimental revenue that churns? Incumbents often hold the distribution edge: assistants bundled with iOS/Android, Windows Copilot, Chrome, Salesforce Einstein, ServiceNow Now Assist—but not always.
I think the theme for 2026 will be COGS and the path to profitability. Big Tech companies like Google can sustain selling at a loss much longer than new companies that run on VC money.
VC money can fund the land-grab, but it won’t cover bad unit economics forever. AI startups are adapting: default to smaller, cheaper models, reserve capacity for peaks, and cache aggressively. The dominant approach is becoming price to outcomes—per case closed, per ticket resolved—with options for guaranteed throughput, so revenue tracks real results, not chatter. Winners pair cost discipline with pricing that meters actual value.
The industry is clearly moving from a “too good to be true” pricing model to something more “usage-based”, to pass the real costs to users and start building margins.
From a more foundational perspective, the main question is whether we are approaching a plateau of performance and capabilities, or not. The model releases in 2025 felt like less of a leap forward compared to previous years. I think1 we are reaching the stability phase, but the debate is still open:
Some top researchers—including guests on our MAD Podcast (Sholto Douglas, Julian Schrittwieser, Jerry Tworek)—say there’s still plenty of low-hanging fruit and years of progress ahead using the current pre-training + RL paradigm. Others urge caution: Andrej Karpathy says “agents are a decade away”; Rich Sutton’s Bitter Lesson argues that general methods plus compute beat hand-tuning; Yann LeCun pushes world models and self-supervised prediction as a different path. The debate is healthy: less leaderboard theater, more ablations, red-teaming, and real-world tasks.
One interesting note is about open source weights models. The DeepSeek’s R1 moment in January 2025 took the world by storm, and for a while it seemed like the world was ending. Now the situation is more hybrid, a mix of close and open models:
DeepSeek’s R1 moment (and open-weights derivatives) set the tone, but Llama 4 underwhelmed and Meta signaled a tighter stance on permissive releases. Mistral had swings, then regained momentum; Qwen3 quietly became the “good-enough” workhorse in many stacks. […] The future seems hybrid: route to open source when you can, spike to frontier when you must.
In terms of capacity constraints, Mark notices how the bottleneck is energy, rather than GPUs:
Energy becomes the new compute chokepoint, and nations notice. Power, not GPUs, is the new bottleneck. Datacenter location decisions now follow megawatt contracts, water rights and grid interconnects. […] Power-first incentives will shape where models are trained and which regions win the AI buildout. Export controls still matter, but kilowatts now set the timelines.
Finally, with all the AI chit-chat we forget that good old-fashioned Data still exists. It is not as cool as during the Modern Data Stack days, but it is still important to enable real world applications, especially in enterprise settings:
Yet the data fundamentals remain more important than ever. Robust tables and catalogs, quality and lineage, and low-latency query engines have become prerequisites for agents, retrieval, and eval-first CI—not afterthoughts. [...] Data isn’t fading; it’s been promoted to AI’s control surface.
Do you like this post? Of course you do. Share it on Twitter/X, LinkedIn and HackerNews
… or I hope? The pace of change has been insane in the last 3 years, it’s so hard to keep up.