
Spec-driven development
Documentation first, SQL second


In the last few months we have been working on an agent to help users of our data warehouse discover and query data. In the name of self-serve, instead of asking an analyst to find the right table and write the SQL, you ask the agent and it searches the catalog, finds relevant tables, answers the question. The agent can be invoked in Slack with a slash command, which launches a cloud agent in the backend that impersonates the user when querying, generates a PR with the result of the research, and returns the results itself as a Slack message. Or it can be executed directly in Claude Code as a custom skill.
When we did an evaluation we learned that the accuracy of the responses improved significantly when the agent had good context about the data. But we also discovered that the response time was much smaller, which is good to save tokens. A well-documented table produced answers 2x to 3x faster compared to tables with raw data and only schema information, because the agent didn’t have to explore, take samples and infer. It could read, understand, and execute.
Context is becoming very valuable, context engineering is the new hot topic, and we have almost none of it. Because context is like documentation, and nobody likes to write documentation.
The context our agent currently uses is cobbled together from code: table schemas, column names, data types, samples of raw data. Not perfect but it works. At exactly the moment AI makes context more valuable, we discovered how little of it we have built.
How pipelines get built today
The standard workflow for building a data pipeline looks something like this. You pull a sample of the source data, spend time understanding its shape, figure out the grain you want, decide whether you need a full refresh or an incremental load, write the SQL, wire up the DAG, and maybe, if you’re disciplined, add some documentation at the end.
That workflow is well tested, and a moderate application of AI doesn’t change it dramatically. What AI can easily do is speed up two steps inside it: writing SQL (faster now) and writing documentation (easier now). The structure is the same, the goal is the same, and the outcome is still trying to produce code.
However, these are tough times for software engineering. People are starting to think seriously about what AI actually does to the discipline. Steve Yegge describes eight levels of AI adoption. Level one is zero or near-zero AI use. By level four, your agent fills the screen and code is just something you review in diffs. By level six, you are running three to five agents in parallel from the CLI. Levels seven and eight involve managing dozens of agents and building your own orchestration infrastructure. Some of the upper levels might be a bit speculative, but the direction of travel is clear.
Software engineers are debating which level they are currently at, and how AI is re-inventing the profession. So when it comes to analytics engineering one of the thoughts that I had was the following: what if we explore the data, write a spec collaboratively with an AI, then let an agent generate the code. The spec is where you spend most of your time. The code comes out at the end, automatically.
This is more than just adding a bit of AI. The traditional workflow treats code as the primary artifact and documentation as an optional afterthought. The spec-driven workflow inverts that: the spec is the primary artifact, where the analytics engineer spends the most time, while the code is a side effect.
What goes in a spec? Things like the grain of the output table. The aggregation logic. The pipeline type and the reasoning behind it. The business rules that govern edge cases. The source assumptions: what you’re trusting upstream data to do, and what happens when it doesn’t.
Here’s a short example, fictional but close to what this could look like in practice:
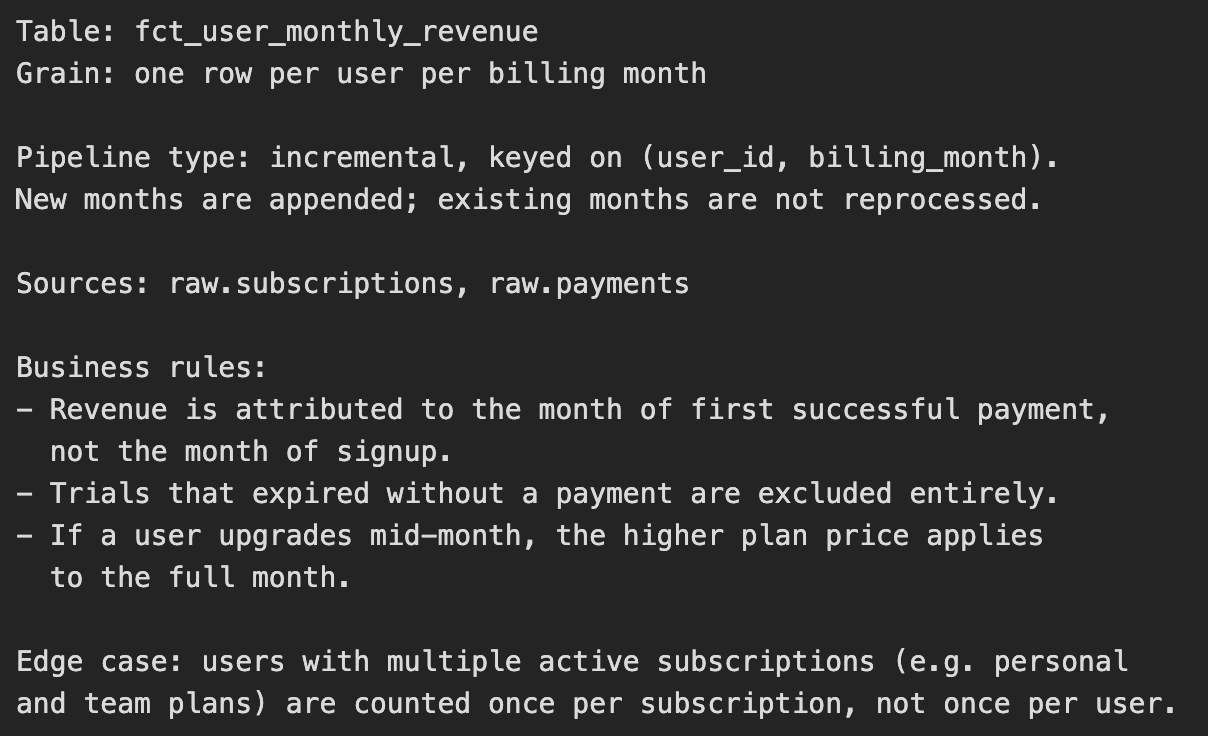
Writing that takes real work. It requires precision of thought, domain knowledge, and the ability to ask the right questions of the data and the stakeholders who defined the business rules. AI helps here, but as a thinking partner, not a booster. You go back and forth until the spec is tight. Then you hand it to an agent. The agent generates the SQL, the DAG, the tests. You review the output. The code is a by-product of having thought carefully about the problem.
The spec serves two jobs
The spec is input to code generation, but it’s also documentation, for humans and agents alike. Every data team has the same problem: six months after a pipeline is built, nobody remembers why it was built that way. The SQL has logic baked into it that used to make sense, and now nobody can tell whether it’s intentional or accidental. The original author has moved on. The new engineer reverse-engineers intent from query structure, which is a hard way to understand business logic.
A spec solves this cleanly because it is readable and it explains the decisions. A new engineer can understand the pipeline in twenty minutes instead of two days. And as AI agents become more involved in data land, a spec is exactly the kind of precious structured context they can consume reliably.
One could argue that a specification precise enough to generate correct code is just code by another name. Natural language cannot achieve the required precision, so the spec becomes pseudocode, then code, and you have gained nothing except an intermediate artifact.
However, I think analytics engineering is different from software engineering in general. The precision a pipeline spec requires is a different kind of precision. You need to be exact about grain: is this one row per user per day, or one row per user per calendar month? You need to be exact about business rules: do we count a conversion in the month the user first paid, or the month they signed up? These questions have exact answers, and a domain expert can write them in plain language, and an agent can implement them correctly. Pipeline logic is business logic, and business logic is a better fit to be written in sentences.
I reckon this approach is just a thought for now and not tested in the wild, but it’s a promising direction that I want to explore with my team.
Do you like this post? Of course you do. Share it on Twitter/X, LinkedIn and HackerNews